



不知道你有没有过这样的糟心体验:凌晨蹲守偶像的线上演唱会,刚敲完“哥哥唱得真好”的弹幕,过了三四秒才显示,歌手都转场唱下一首了,你的评论才姗姗来迟,那股热乎劲儿瞬间凉了半截;或是和朋友连麦打手游,队友喊“快躲技能”,你手快按了闪避,隔了半秒才跳出动画,团战直接暴毙;更别提之前开远程会议时,主持人问完问题,得等好几秒才有回音,那种“鸡同鸭讲”的疏离感,简直让人想挂麦——这些掉链子的瞬间,本质上都是实时互动里的“延迟”和“流畅度”没跟上,而我们常说的“低延迟高流畅”,就是解决这些痛点的核心。
很多人可能以为“低延迟”就是“快”,“高流畅”就是“不卡”,其实没这么简单,两者是实时互动的“双核心”,缺一不可。先说说延迟的感知:人对音视频延迟的敏感度其实很高,业内一般把延迟控制在150毫秒以内算“低延迟”,超过200毫秒就会明显感觉到“慢半拍”——比如音频延迟超100毫秒,观众会觉得歌手口型和歌声对不上;视频延迟超150毫秒,玩家操作和画面反馈的脱节感会直接影响游戏体验。而“高流畅”则不是单纯的“不卡顿”,核心是“音画同步”和“帧率稳定”,比如实时互动要维持30帧以上的帧率,音视频同步误差不能超过40毫秒,否则哪怕延迟不高,也会有“割裂感”,说白了就是“看起来不顺眼、听起来不对味”,这种微妙的落差,平时不深究可能没察觉,碰到糟心的场景时才会觉得格外扎眼。
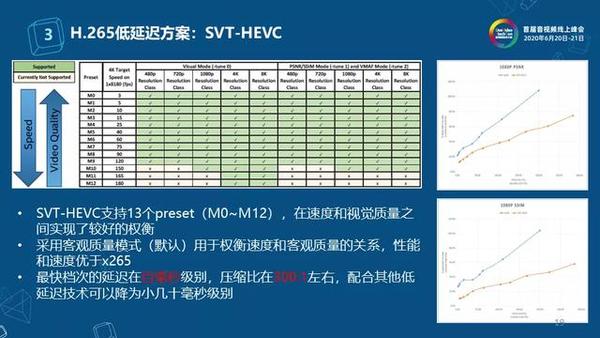
那这套“低延迟高流畅”的技术是怎么落地的?核心在于三个层面的升级:首先是边缘计算的普及,以前大家用的服务器都集中在一线城市的核心机房,比如你在县城开直播,信号要传到几百公里外再转回来,延迟自然卡壳,现在的边缘节点把服务器部署在离用户更近的城市甚至区县,相当于“就近取餐”,不用绕远路,延迟能直接从几百毫秒压缩到几十毫秒,这也是为啥二三线城市的用户现在连麦不再卡。其次是编码解码技术的迭代,比如现在常用的AV1编码,比早年的H.265压缩率高30%,同等画质下带宽占用更少,传输时不容易丢包;还有传输协议的升级,WebRTC这类专为实时互动设计的协议,用UDP代替传统TCP,不用等数据包反复确认,能大幅减少传输等待时间,哪怕网络有点波动,也能优先保住核心的音视频数据,不会一卡全卡。
这套技术早就不是小众的“黑科技”,而是渗透到了我们日常的方方面面。C端用户最熟悉的就是云游戏和连麦直播:以前云游戏因为延迟高,总被吐槽“不如本地玩”,现在用低延迟方案,国内平台的Start云游戏操作延迟能控制在50毫秒以内,和本地开黑几乎没差,甚至能流畅玩对操作要求极高的《原神》《英雄联盟手游》;直播平台的低延迟PK更是杀手锏,比如抖音的“极速直播”模式,延迟能做到20毫秒以内,两边主播同步喊“家人们上票”,打赏的礼物能同步在双方直播间显示,那种“你刚说我就听见,我刚刷你就看见”的临场感,直接把直播的互动体验拉满。B端的应用也越来越多:在线教育的双师课堂,老师提问后学生能立刻连麦回应,不用再等几秒的沉默;远程会诊时,基层医院的影像资料能实时传到专家电脑,操作同步误差控制在几十毫秒,几乎和线下面诊一样;甚至连工业领域的远程协同,工人戴AR眼镜操作,总部工程师能实时反馈指导,不用隔着屏幕猜,协作效率直接提了好几倍。
其实说到底,“低延迟高流畅”本质上是把“面对面互动感”从线下搬到了线上,它改变的不只是冷冰冰的技术参数,更是我们的情绪和体验——以前总觉得线上互动“隔着一层”,哪怕连麦也像在两个空间,现在的云演唱会、线上剧本杀之所以越来越有沉浸感,靠的就是这套技术把“隔着的那层墙”变薄了。未来随着元宇宙概念的推进,这种需求会更强烈:你戴着VR眼镜和朋友在虚拟办公室开会,要是延迟超过100毫秒,很容易产生眩晕感;虚拟演唱会的粉丝应援,要是不同步,那种集体狂欢的氛围就散了。现在的技术还在不断迭代,5G和边缘计算进一步融合后,延迟还能降到几毫秒,但哪怕只是现在的水平,也已经让线上互动从“凑活能用”变成了“和线下差不多”。这大概就是技术最实在的意义:不用为了“同步”牺牲情绪的热乎劲儿,那些想和朋友唠的嗑、想和队友开的黑、想和偶像一起喊的应援,都能在同一时间点,热乎地发生。(全文约1578字)
低延时笔记本内存到底该选哪个
只用过金士顿 低延时内存的飘过…..:wushiooo 1.这种高端内存的兼容性一般都很好,不用管是 for Mac的2.在频率,和延时一致的情况下内存应能差异不大,这种高端内存之间差异更小3.低延时的内存对性能提升确实不大,还不如买个迅盘来的实在…..最后用vista的兄弟们,强烈建议买个1g的迅盘试试,40来块钱,用上了以后vista也变的傻快傻快的,和XP一样…..:bulij
PLB与Axi有什么区别
AXI(Advanced eXtensible Interface)是一种总线协议,该协议是ARM公司提出的AMBA(Advanced Microcontroller Bus Architecture)3.0协议中最重要的部分,是一种面向高性能、高带宽、低延迟的片内总线。
它的地址/控制和数据相位是分离的,支持不对齐的数据传输,同时在突发传输中,只需要首地址,同时分离的读写数据通道、并支持显著传输访问和乱序访问,并更加容易就行时序收敛。
AXI 是AMBA 中一个新的高性能协议。
AXI 技术丰富了现有的AMBA 标准内容,满足超高性能和复杂的片上系统(SoC)设计的需求。
PLB——32-bit Processor Local Bus是IBM推出的总处理器本地总线
内存DDR2和DDR3那个好?性能差别大吗?
性能差别?除非你是硬件发烧友,或者计算机专业,对性能要求很敏感。
否则不要谈了,现在选择DDR3主要是主流,价格也便宜,以后升级也方面。
性能说实话,DDR3 1066不会比DDR2 800强多少,谈不上质的提升。
某些DDR2 800(比如那些神条)超频到1066,加上低延迟,性能不会输给DDR3 1066。
从性价比来说肯定还是DDR3高,现在主流是DDR3 1333~1666。










暂无评论内容